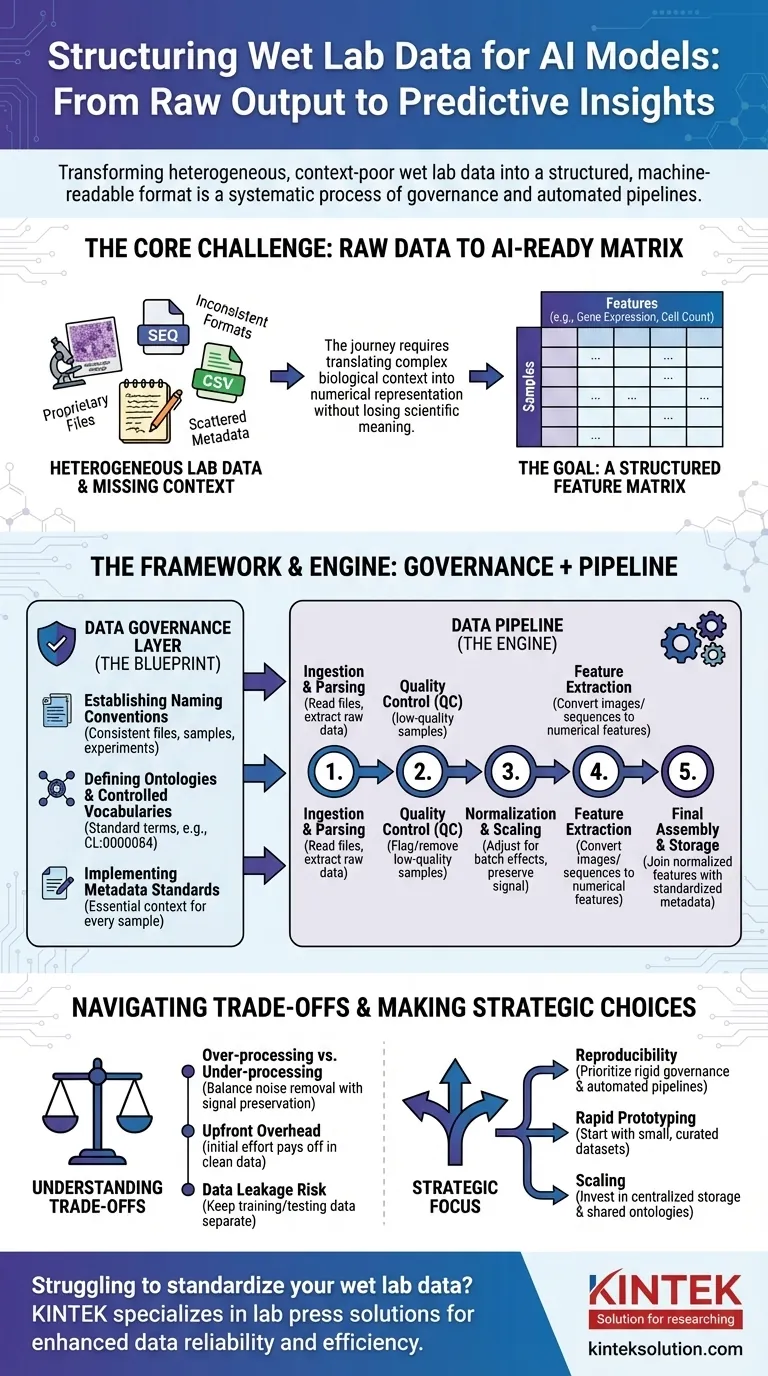
Para preparar los datos de laboratorio húmedo para la IA, debe transformarlos de su estado bruto, a menudo inconsistente, a un formato estructurado y legible por máquina. Este no es un solo paso, sino un proceso sistemático que implica la gobernanza de datos para crear reglas claras, seguido de tuberías de datos que automatizan la limpieza, normalización y estructuración de los resultados experimentales brutos en un formato consistente adecuado para el entrenamiento del modelo.
El desafío principal no es simplemente reformatear archivos. Se trata de traducir sistemáticamente el complejo contexto biológico —como las condiciones experimentales, el historial de las muestras y las técnicas de medición— en una representación numérica estructurada de la que un modelo de IA pueda aprender sin perder un significado científico crítico.

El problema central: De la salida bruta a los datos listos para la IA
El camino desde el banco de laboratorio hasta un modelo predictivo está plagado de desafíos de datos. La salida bruta de los instrumentos científicos rara vez, o nunca, está lista para su uso directo en un algoritmo de IA.
La heterogeneidad de los datos de laboratorio
Los datos de laboratorio húmedo vienen en una vasta gama de formatos. Esto incluye desde archivos propietarios de secuenciadores y microscopios hasta simples CSV de lectores de placas, cada uno con su propia estructura y peculiaridades.
Sin embargo, un modelo de IA requiere un formato unificado.
La maldición del contexto faltante
La información crítica, o metadatos, a menudo está dispersa. Podría estar en el cuaderno de un científico, en una hoja de cálculo separada o simplemente en su cabeza. Sin este contexto (por ejemplo, qué fármaco se aplicó, la temperatura, la línea celular utilizada), los datos numéricos carecen de significado.
El objetivo: Una matriz de características
En última instancia, la mayoría de los modelos de IA necesitan datos en una matriz de características. Esta es una tabla simple donde las filas representan muestras individuales (por ejemplo, un paciente, un pozo de cultivo celular) y las columnas representan características (por ejemplo, niveles de expresión génica, mediciones de morfología celular, concentraciones de proteínas).
Un marco para la estandarización: La capa de gobernanza de datos
Antes de poder construir tuberías automatizadas, debe establecer reglas. Esto es la gobernanza de datos, el plan que garantiza la coherencia en todos los experimentos y equipos. Es el paso más crítico y a menudo pasado por alto.
Establecimiento de convenciones de nomenclatura
Una regla simple pero poderosa es aplicar un esquema de nomenclatura consistente para archivos, muestras y experimentos. Esto permite que los datos se vinculen y rastreen programáticamente desde su origen hasta el análisis final.
Definición de ontologías y vocabularios controlados
Una ontología proporciona un conjunto estándar de términos para describir entidades biológicas. Por ejemplo, en lugar de permitir "célula T", "linfocito T" y "célula-T", un vocabulario controlado impone un solo término, como CL:0000084 de la Ontología Celular.
Esto evita la ambigüedad y asegura que los datos de diferentes experimentos sean verdaderamente comparables.
Implementación de estándares de metadatos
Debe definir los metadatos mínimos que deben capturarse para cada muestra. Esto a menudo incluye la fuente de la muestra, las condiciones experimentales, la configuración del instrumento y la fecha. Esta regla asegura que ningún punto de datos se convierta en un huérfano, separado de su contexto.
El motor de la transformación: Construyendo la tubería de datos
Con las reglas de gobernanza implementadas, puede construir una tubería de datos. Esta es una serie de pasos de software automatizados que transforma los datos brutos en la matriz de características final lista para la IA.
Paso 1: Ingesta y análisis de datos
El primer trabajo de la tubería es encontrar y leer los archivos de datos brutos. Este paso implica escribir analizadores específicos para el formato de salida de cada instrumento para extraer las mediciones primarias y cualquier metadato asociado.
Paso 2: Control de calidad (QC)
No todos los datos son datos buenos. La tubería debe marcar o eliminar automáticamente las muestras de baja calidad basándose en métricas predefinidas, como recuentos bajos de células en un experimento de imagen o baja calidad de lectura de un secuenciador.
Paso 3: Normalización y escalado
Las mediciones de diferentes lotes o placas a menudo tienen variaciones técnicas. La normalización es un paso crucial que ajusta los datos para hacer que las mediciones sean comparables entre experimentos, eliminando el ruido técnico mientras se preserva la señal biológica.
Paso 4: Extracción de características
Los datos brutos a menudo no están en un formato de características. Una imagen, por ejemplo, debe procesarse para extraer características numéricas como el tamaño, la forma y la intensidad de la célula. Una secuencia de ADN podría convertirse en un vector de frecuencia de k-mers. Este paso convierte datos complejos en números que la IA puede usar.
Paso 5: Ensamblaje final y almacenamiento
Finalmente, la tubería une las características normalizadas con los metadatos estandarizados. Esto crea la matriz de características final y limpia, que luego se guarda en un formato estable y consultable (como Parquet o una base de datos) para el entrenamiento del modelo.
Entendiendo las compensaciones
La estructuración de datos no es un proceso neutral. Cada elección que haga puede influir en el rendimiento y la interpretación final del modelo.
Sobreprocesamiento vs. subprocesamiento
La normalización o el filtrado agresivos a veces pueden eliminar señales biológicas sutiles pero importantes. Por el contrario, no eliminar el ruido técnico garantizará que su modelo aprenda de artefactos experimentales en lugar de biología. Este es un equilibrio constante.
La estandarización crea una sobrecarga inicial
La implementación de la gobernanza de datos requiere un esfuerzo inicial significativo y la aceptación de todo el equipo. Puede parecer que ralentiza la investigación al principio, pero paga dividendos masivos al evitar meses de trabajo de limpieza más adelante.
El peligro de la fuga de datos
Una función crítica de la tubería es mantener separados los datos de entrenamiento y prueba. Si la información del conjunto de prueba (por ejemplo, su distribución general) se utiliza para normalizar el conjunto de entrenamiento, el rendimiento de su modelo se inflará artificialmente y fallará en el mundo real.
Tomando la decisión correcta para su objetivo
Su enfoque para la estructuración de datos debe guiarse por su objetivo final.
- Si su enfoque principal es la reproducibilidad: Priorice la gobernanza rígida de datos y las tuberías totalmente automatizadas y con control de versiones desde el primer día.
- Si su enfoque principal es la creación rápida de prototipos: Comience con un conjunto de datos pequeño y curado manualmente para validar su enfoque de IA antes de invertir en una tubería a gran escala.
- Si su enfoque principal es escalar en una organización grande: Invierta mucho en almacenamiento centralizado de datos, ontologías compartidas y componentes comunes de tuberías para evitar silos de datos.
En última instancia, tratar sus datos con el mismo rigor que sus experimentos de laboratorio húmedo es la base para construir una IA biológica exitosa y confiable.
Tabla resumen:
| Paso | Acción clave | Propósito |
|---|---|---|
| Gobernanza de datos | Establecer convenciones de nomenclatura, ontologías, estándares de metadatos | Garantizar la coherencia y la comparabilidad entre experimentos |
| Tubería de datos | Ingerir, analizar, QC, normalizar, extraer características, ensamblar | Automatizar la transformación de datos brutos en una matriz de características lista para la IA |
| Compensaciones | Equilibrar el sobreprocesamiento vs. el subprocesamiento, gestionar la sobrecarga | Optimizar el rendimiento del modelo y evitar la fuga de datos |
¿Tiene dificultades para estandarizar sus datos de laboratorio húmedo para la IA? KINTEK se especializa en máquinas de prensado de laboratorio, incluyendo prensas de laboratorio automáticas, prensas isostáticas y prensas de laboratorio calentadas, sirviendo a laboratorios para mejorar la fiabilidad de los datos y la eficiencia experimental. Permítanos ayudarle a lograr resultados consistentes —contáctenos hoy mismo para discutir sus necesidades y descubrir cómo nuestras soluciones pueden apoyar su investigación impulsada por IA!
Guía Visual